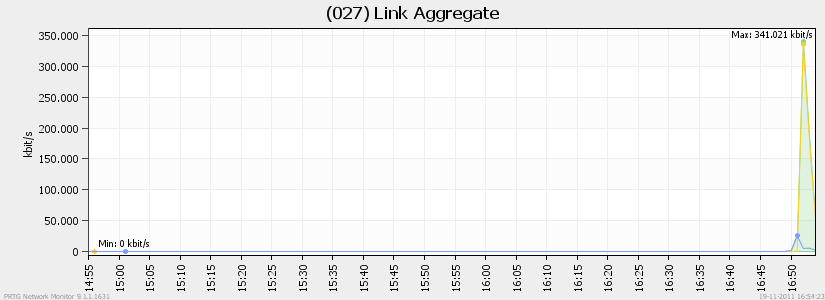
Update, I managed to get down MPIO. Some new benchmarks, some of them I question (mostly seeker). Besides from the guide, which I got down on vSphere 5, I made all the vSwitches eat Jumbo (9K frames).
dd command (2x executed with 2 hour gaps:
Code:
[root@localhost ~]# dd if=/dev/zero of=/var/tmpMnt bs=1024 count=12000000
12000000+0 records in
12000000+0 records out
12288000000 bytes (12 GB) copied, 74.6241 seconds, 165 MB/s
[root@localhost ~]# dd if=/dev/zero of=/var/tmpMnt bs=1024 count=12000000
12000000+0 records in
12000000+0 records out
12288000000 bytes (12 GB) copied, 73.7074 seconds, 167 MB/s
seeker:
Code:
[root@localhost ~]# ./seeker /dev/sda
Seeker v2.0, 2007-01-15, http://www.linuxinsight.com/how_fast_is_your_disk.html
Benchmarking /dev/sda [51200MB], wait 30 seconds..............................
Results: 912 seeks/second, 1.10 ms random access time
[root@localhost ~]# ./seeker /dev/sda
Seeker v2.0, 2007-01-15, http://www.linuxinsight.com/how_fast_is_your_disk.html
Benchmarking /dev/sda [51200MB], wait 30 seconds..............................
Results: 934 seeks/second, 1.07 ms random access time
hdparm:
Code:
Timing buffered disk reads: 302 MB in 3.01 seconds = 100.50 MB/sec
I think there still could be some as mentioned here and here.
Any thoughts?










 Reply With Quote
Reply With Quote
